Видео с ютуба Swe-Bench Pro

SWE-Bench is getting replaced???

За пределами SWE-Bench Pro — что дальше будут делать агенты?

Цепочка мыслей | Представляем SWE-Bench Pro

SWE Bench Verified - AI Benchmark

Как интерпретировать новые результаты SWE-Bench для GLM-5.1

The End of SWE-Bench Verified — Mia Glaese & Olivia Watkins, OpenAI Frontier Evals

GLM-5.1 Beat GPT-5.4 on SWE-Bench Pro — Did China Just Win the Coding War?

What do AI Benchmarks Actually Mean?! A Fast Breakdown (MMLU, SWE-bench, & More Explained)
What is Swe Bench Pro?

Что такое SWE Bench?

SWE-BENCH: CAN LANGUAGE MODELS RESOLVE REAL-WORLD GITHUB ISSUES?

SWE-Bench Pro: Can AI Agents Solve Long-Horizon Software Engineering Tasks?

Claude Opus 4.8 CHEGOU — 69.2% no SWE-Bench Pro 😳

SWE Bench Pro:AI编程的现实考验
![[State of Code Evals] After SWE-bench, Code Clash & SOTA Coding Benchmarks recap — John Yang](https://imager.clipsaver.ru/MxB-xRGXxkk/max.jpg)
[State of Code Evals] After SWE-bench, Code Clash & SOTA Coding Benchmarks recap — John Yang

SWE Bench Contamination

Оценка агентов на SWE-Bench

SWE-Bench authors reflect on the state of LLM agents at Neurips 2024

🤯¡El test SWE bench verified!💻 500 retos de GitHub para saber si la IA sabe programar🔥
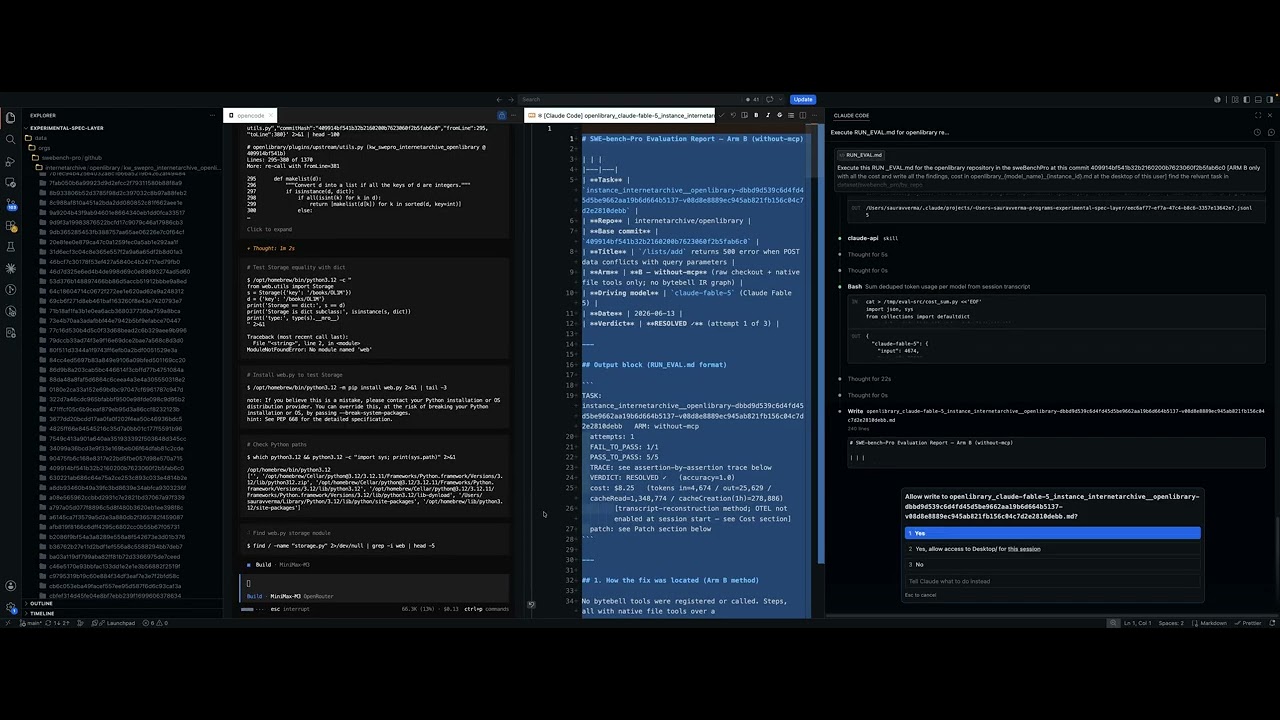
SWE-bench Pro real run: same task resolved, 25x cheaper with open source AI. Bytebell.ai